
Spark 运行架构
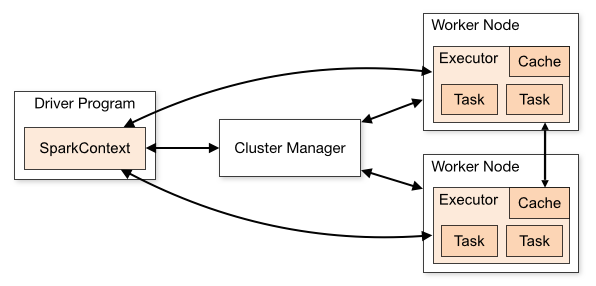
Spark架构采用了分布式计算中的Master-Slave模型。Master是对应集群中的含有Master进程的节点,Slave是集群中含有Worker进程的节点。Master作为整个集群的控制器,负责整个集群的正常运行;Worker相当于计算节点,接收主节点命令与进行状态汇报;Executor负责任务的执行;Client作为用户的客户端负责提交应用,Driver负责控制一个应用的执行。
Spark集群部署后,需要在主节点和从节点分别启动Master进程和Worker进程,对整个集群进行控制。在一个Spark应用的执行过程中,Driver和Worker是两个重要角色。Driver 程序是应用逻辑执行的起点,负责作业的调度,即Task任务的分发,而多个Worker用来管理计算节点和创建Executor并行处理任务。在执行阶段,Driver会将Task和Task所依赖的file和jar序列化后传递给对应的Worker机器,同时Executor对相应数据分区的任务进行处理。
Spark 组件
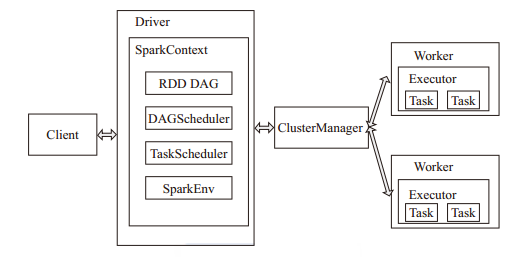
- ClusterManager:在Standalone模式中即为Master(主节点),控制整个集群,监控Worker。在YARN模式中为资源管理器。
- Worker:从节点,负责控制计算节点,启动Executor或Driver。在YARN模式中为NodeManager,负责计算节点的控制。
- Driver:运行Application的main()函数并创建SparkContext。
- Executor:执行器,在worker node上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executors。
- SparkContext:整个应用的上下文,控制应用的生命周期。
- RDD:Spark的基本计算单元,一组RDD可形成执行的有向无环图RDD Graph。
- DAG Scheduler:根据作业(Job)构建基于Stage的DAG,并提交Stage给TaskScheduler。
- TaskScheduler:将任务(Task)分发给Executor执行。
- SparkEnv:线程级别的上下文,存储运行时的重要组件的引用。
- SparkConf:负责存储配置信息。
Spark 提交Job
参考: http://spark.apache.org/docs/latest/submitting-applications.html
可向 本地 或 集群 提交。
推荐一本书
《Advanced Analytics with Spark. 2015.4》
生态
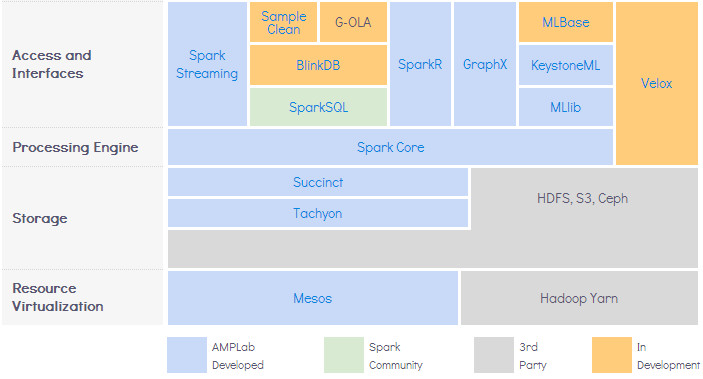
Spark can integaration with Hadoop ecosystem.
- 1.Avro and Parquet can store data on Hadoop.
- 2.Can read and write to NoSQL databases like HBase and Cassandra.
- 3.Spark Streaming can ingest data from Flume and Kafka.
- 4.SparkSQL can interact with Hive Metastore.
- 5.It can run inside YARN, Hadoop’s scheduler and resource manager.