
Kafka 具有3大功能:
- 1.Publish & Subscribe: to streams of data like a messaging system
- 2.Process: streams of data efficiently
- 3.Store: streams of data safely in a distributed replicated cluster

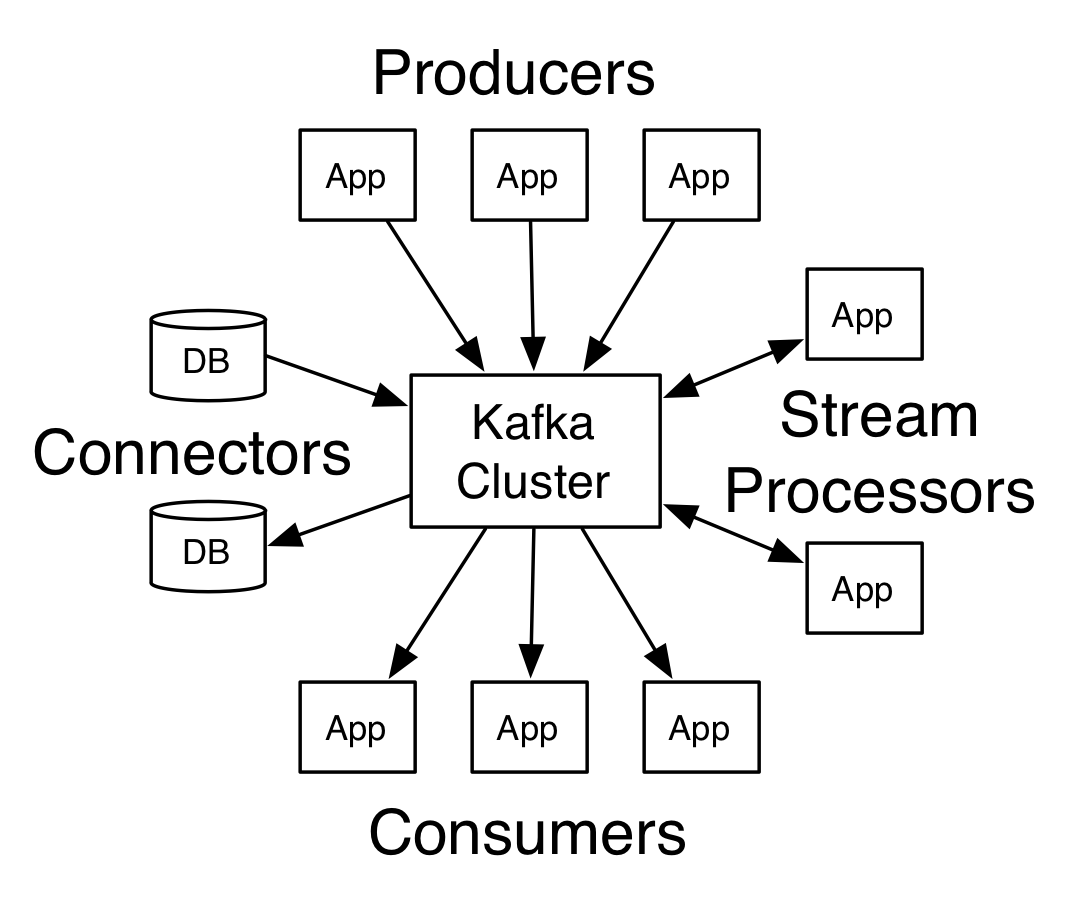
Producer & Consumer 导图
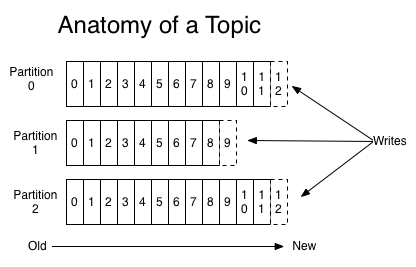
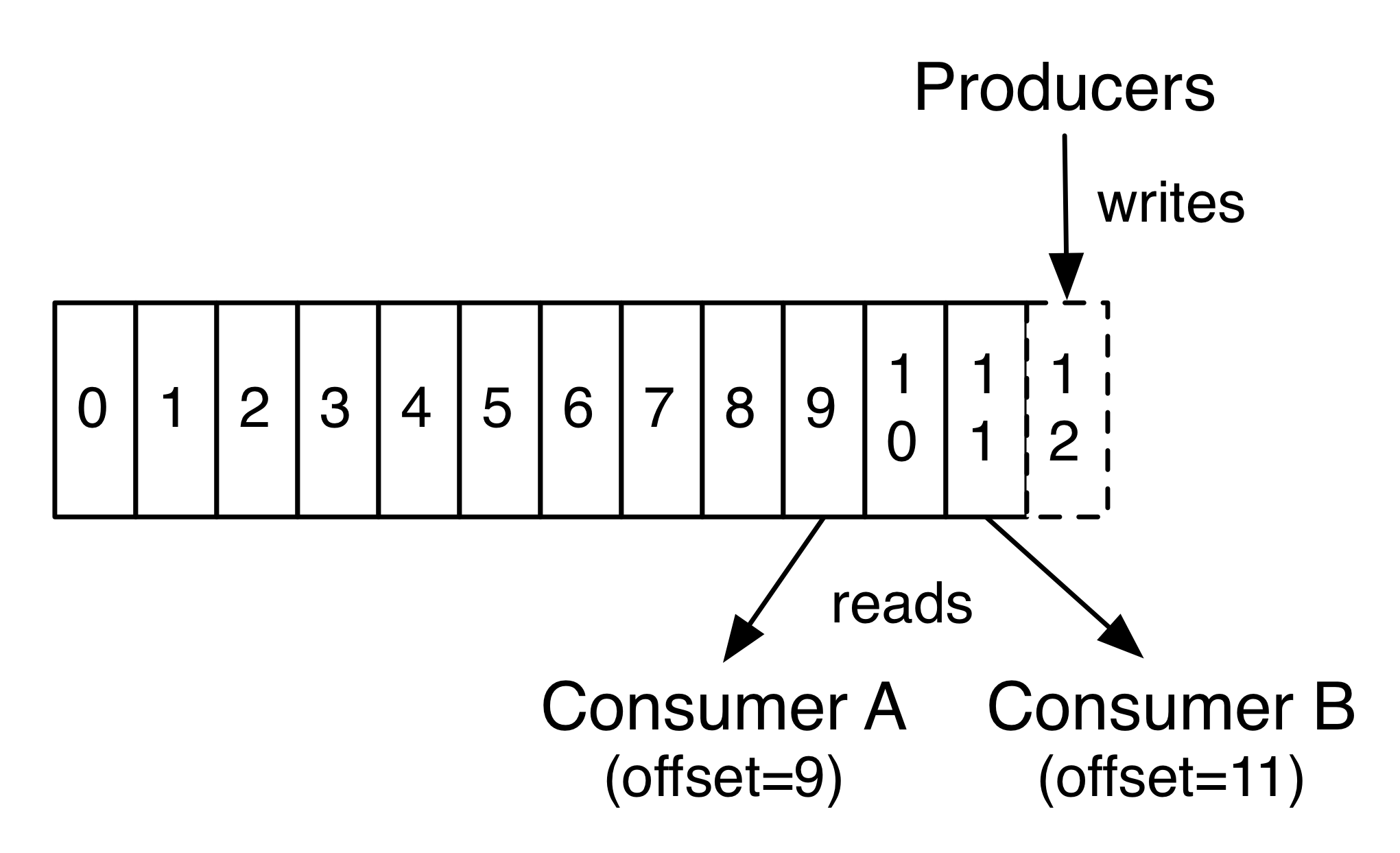
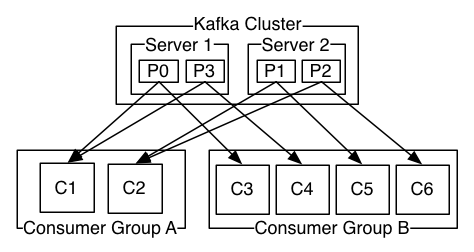
Kafka four core APIs
Kafka has four core APIs:
- The Producer API allows an application to publish a stream records to one or more Kafka topics.
- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
- The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
- The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems.
Producer APIs
kafka.producer.SyncProducer and kafka.producer.async.AsyncProducer.
can handle queueing/buffering of multiple producer requests and asynchronous dispatch of the batched data
kafka.producer.Producerprovides the ability to batch multiple produce requests (producer.type=async), before serializing and dispatching them to the appropriate kafka broker partition. The size of the batch can be controlled by a few config parameters. As events enter a queue, they are buffered in a queue, until either queue.time or batch.size is reached. A background thread (kafka.producer.async.ProducerSendThread) dequeues the batch of data and lets thekafka.producer.EventHandlerserialize and send the data to the appropriate kafka broker partition. A custom event handler can be plugged in through the event.handler config parameter. At various stages of this producer queue pipeline, it is helpful to be able to inject callbacks, either for plugging in custom logging/tracing code or custom monitoring logic. This is possible by implementing thekafka.producer.async.CallbackHandlerinterface and settingcallback.handlerconfigparameter to that class.handles the serialization of data through a user-specified Encoder:
123interface Encoder<T> {public Message toMessage(T data);}
The default is the no-op kafka.serializer.DefaultEncoder
- provides software load balancing through an optionally user-specified Partitioner:
The routing decision is influenced by the kafka.producer.Partitioner.
Consumer APIs
|
|
Kafka ZooKeeper文件目录
Broker Node Registry:
Broker Topic Registry:
Consumer Id Registry:
Consumer Offsets:
Partition Owner registry: