Hive 简介
参考: https://cwiki.apache.org/confluence/display/Hive/Home
Apache Hive是一个建立在Hadoop架构之上的数据仓库。它能够提供数据的精炼,查询和分析。Apache Hive起初由Facebook开发。
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
- 1.hive是一个数据仓库
- 2.hive基于hadoop。
Hive 安装
参考: http://doctuts.readthedocs.io/en/latest/hive.html
1.安装hadoop
123export HADOOP_HOME=/root/hadoop-2.7.3export HIVE_HOME=/root/apache-hive-2.1.0-binexport PATH=$PATH:$HIVE_HOME/bin2.启动hadoop hdfs文件系统
12bin/hdfs namenode -formatsbin/start-all.sh 或者 start-dfs.sh and start-yarn.sh3.创建文件夹
12bin/hadoop fs -mkdir /usr/hive/warehousebin/hadoop fs -chmod g+w /usr/hive/warehouse4.第一次运行hive之前,需要设置schema
1schematool -initSchema -dbType derby
如果已经尝试运行hive出错之后,再去设置schema也会出错,需要做:
- 5.运行hive1hive
Hive 启动源代码入口:
bin/hive —> hive script中会执行 bin/ext/*.sh, 以及 bin/ext/util/*.sh 命令
SERVICE_LIST 变量 在bin/ext/*.sh 中增加value;
SERVICE 变量在启动命令时 赋值; 默认 SERVICE=”cli”

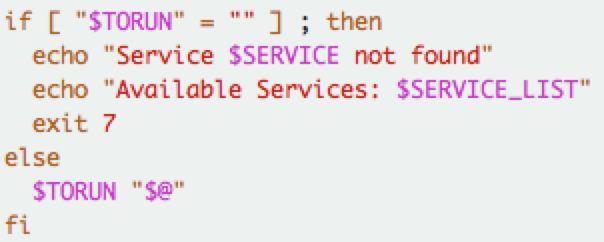
—> execHiveCmd 启动 java 源代码的入口 org.apache.hive.beeline.cli.HiveCli 或者 org.apache.hadoop.hive.cli.CliDriver
Hive vs HBase
共同点:
- 1.hbase与hive都是架构在hadoop之上的。都是用hadoop作为底层存储
区别:
- 1.Hive是建立在Hadoop之上为了减少MapReduce jobs编写工作的批处理系统,HBase是为了支持弥补Hadoop对实时操作的缺陷的项目 。
- 2.想象你在操作RMDB数据库,如果是全表扫描,就用Hive+Hadoop,如果是索引访问,就用HBase+Hadoop 。
- 3.Hive query就是MapReduce jobs可以从5分钟到数小时不止,HBase是非常高效的,肯定比Hive高效的多。
- 4.Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce,Hive中的表纯逻辑。
- 5.hive借用hadoop的MapReduce来完成一些hive中的命令的执行
- 6.hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作。
- 7.hbase是列存储。
- 8.hdfs作为底层存储,hdfs是存放文件的系统,而Hbase负责组织文件。
- 9.hive需要用到hdfs存储文件,需要用到MapReduce计算框架。
improt Hive源代码到Eclipse里面:
- mvn clean install -DskipTests
- mvn eclipse:eclipse -DdownloadSources -DdownloadJavadocs
Hive 知识范围