
HDFS 分布式文件系统
- Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
Hadoop HDFS 1.x vs 2.x
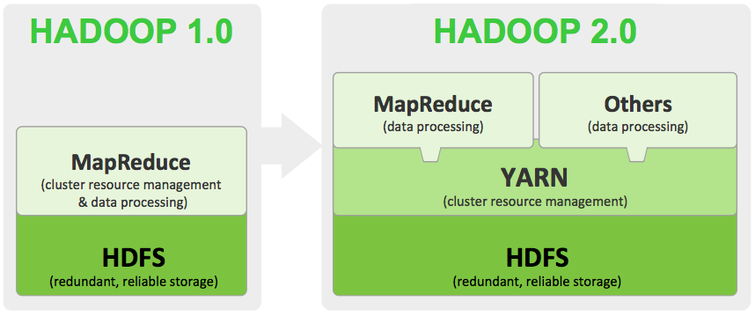
Hadoop HDFS有2个版本,1.x和2.x,两者之间还有比较大的差距:
- 1.x只支持MapReduce运算. 2.x除了MapReduce之外,还支持Spark,MPI,Hama,Giraph等多种类型运算。
- 1.x中的MR组件既分发任务还需要进行资源调度。 2.x由另一个组件YARN来进行资源调度,MR只进行任务分发。
- 1.x无法实现HA,只有一个NameNode管理所有节点。 2.x支持HA,有SecondNameNode,但也只支持冷迁移。2.x还支持了Federation联邦,通过文件系统挂载点,将一个NameNode的负载分发下去。注意:HA和Federation可以结合使用。
网上资料中包含了10点差异,但是从技术/架构角度上来说,这3点变化是核心的。
Hadoop HDFS 2.x 架构图
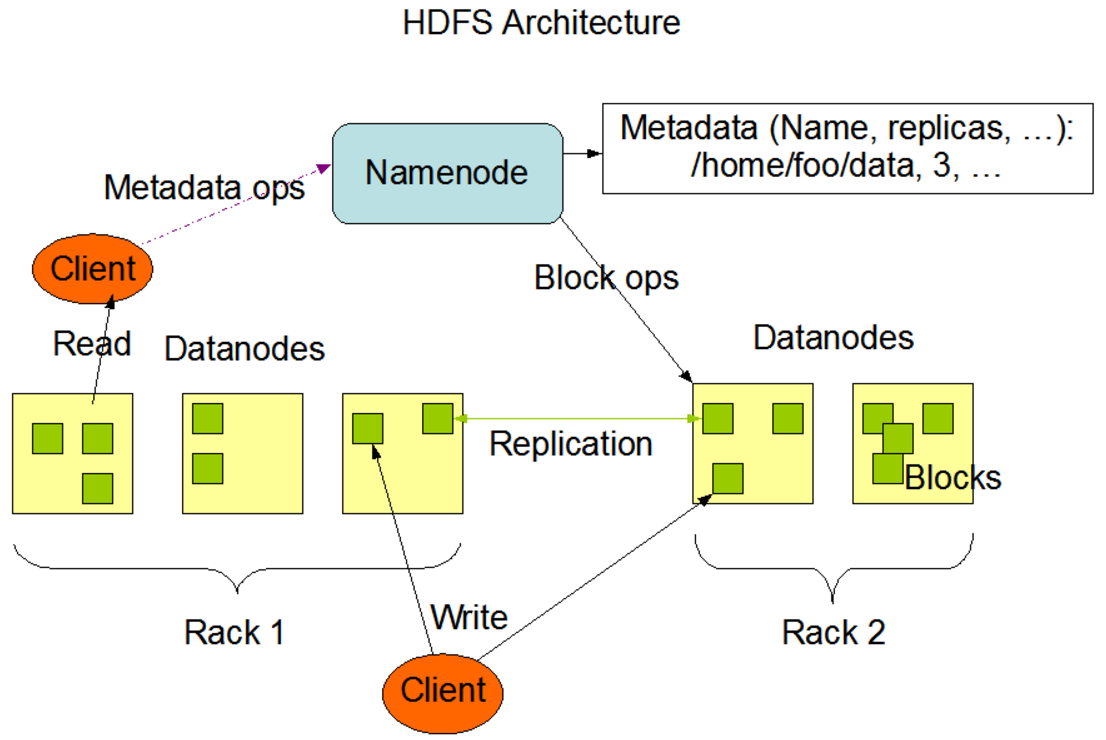
NameNode
HDFS分布式文件系统中的管理者,负责管理文件系统的命名空间,集群配置信息,存储的复制。
Secondary NameNode
并非NameNode的热备份,辅助NameNode,定期合并FSimage和EditLog。在NameNode失效的情况下,可以依据Secondary NameNode本地存储的FSimage和EditLog,恢复自身作为NameNode,但可能会有部分文件丢失,原因在于Secondary NameNode上的FSimage和EditLog并不是实时更新的。
DataNode
DataNode是文件存储的节点,用于存放文件的Block,并且周期性的将Block信息发送给NameNode。值得提一句的是:HDFS中的Block大小设置很有讲究,通常为64M/128M,过小的Block会给NameNode带来巨大的管理压力,过大的Block可能会导致磁盘空间的浪费。
Client
与NameNode交互,获取文件存放位置;再与DataNode交互,读取或写入数据;并且可以管理整个HDFS文件系统。
文件写入过程
- Client向NameNode发起文件写入请求。
- NameNode根据文件大小和文件块配置情况,返回给Client它所管理的DataNode信息。
- Client将文件划分为多个Block,更具DataNode的地址信息,按顺序写入到每一个DataNode块中。
文件读取过程
- Client向NameNode发起文件读取请求。
- NameNode返回文件存储的DataNode信息。
- Client读取文件信息。
HDFS 优缺点
优点
- 处理超大文件
- 流式访问数据,一次写入,多次访问
- 运行于廉价的商用机器上
缺点
- 不适合低延迟的数据访问
- 无法高效存储大量的小文件
- 不支持多用户写入及任意修改文件
Hadoop HDFS 2.x 安装, 关于安装, 请参考博客中的另一篇文章
Hadoop HDFS 2.x 包含了3种安装模式:
- Standalone. 独立模式
- Pseudo-Distributed Operation. 伪分布式
- Cluster. 集群