HBase 简介
HBase 是一个开源的非关系型分布式数据库。 https://azure.microsoft.com/en-us/documentation/articles/hdinsight-hbase-tutorial-get-started-linux/
- HBase架构指南: http://www.guru99.com/hbase-architecture-data-flow-usecases.html
- 安装指南: http://www.guru99.com/hbase-installation-guide.html
- HBase Shell 命令指南: http://www.guru99.com/hbase-shell-general-commands.html
HBase NoSQL 数据库优缺点
Hbase,Casandra,Bigtable都属于面向 列存储 的分布式存储系统。
HBase 基本单元:
- Table: Collection of rows present.
- Row: Collection of column families.
- Column Family: Collection of columns.
- Column: Collection of key-value pairs.
- Namespace: Logical grouping of tables.
- Cell: A {row, column, version} tuple exactly specifies a cell definition in HBase.
列存储 vs 行存储:
Hbase的优点:
1 列的可以动态增加,并且列为空就不存储数据,节省存储空间.
2 Hbase自动切分数据,使得数据存储自动具有水平scalability.
3 Hbase可以提供高并发读写操作的支持
Hbase的缺点:
1 不能支持条件查询,只支持按照Row key来查询.
2 暂时不能支持Master server的故障切换,当Master宕机后,整个存储系统就会挂掉.
HBase 架构
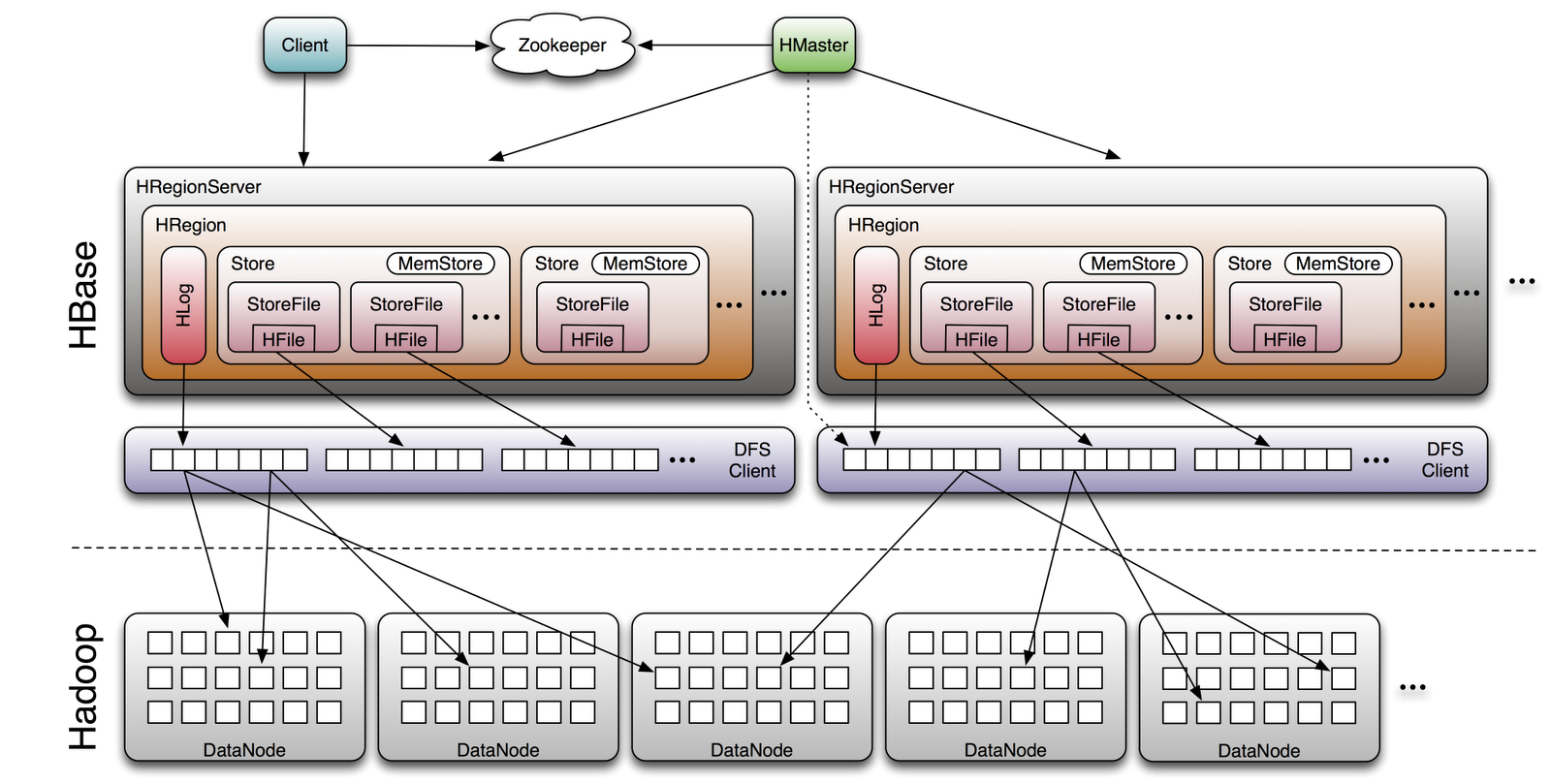
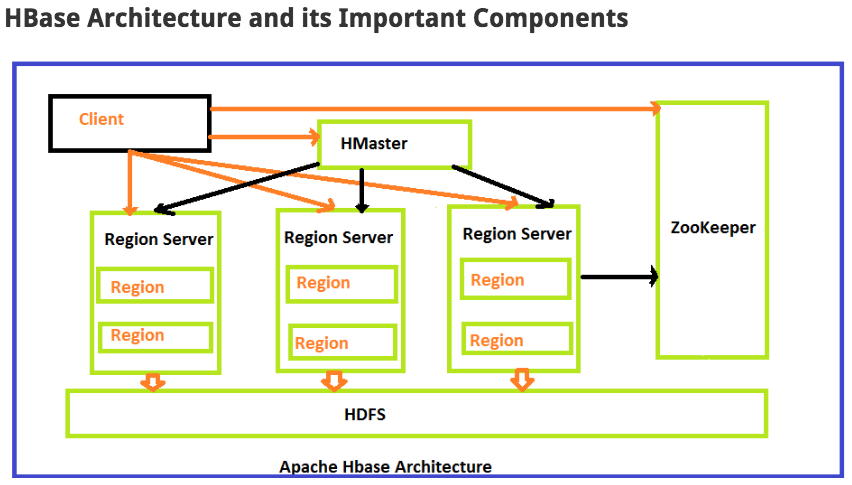
Hbase Data Flow
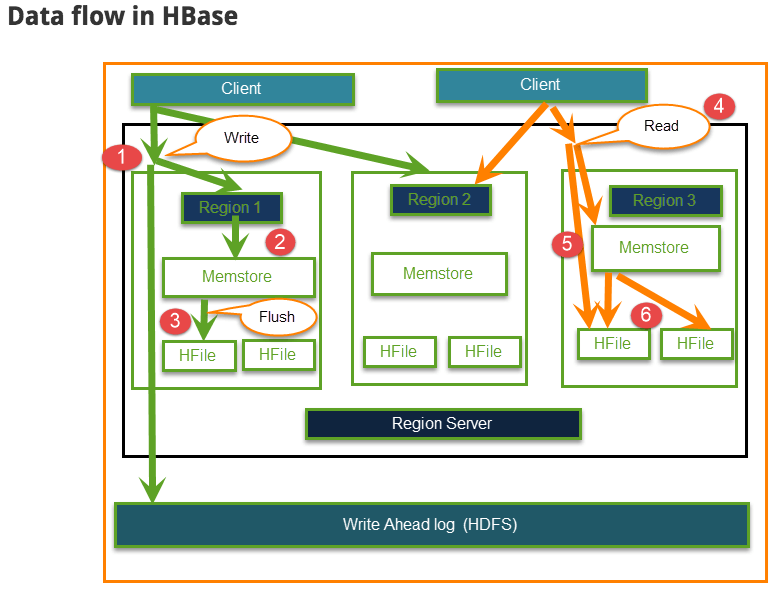
The Read and Write operations from Client into Hfile can be shown in below diagram.
- Step 1) Client wants to write data and in turn first communicates with Regions server and then regions
- Step 2) Regions contacting memstore for storing associated with the column family
- Step 3) First data stores into Memstore, where the data is sorted and after that it flushes into HFile. The main reason for using Memstore is to store data in Distributed file system based on Row Key. Memstore will be placed in Region server main memory while HFiles are written into HDFS.
- Step 4) Client wants to read data from Regions
- Step 5) In turn Client can have direct access to Mem store, and it can request for data.
- Step 6) Client approaches HFiles to get the data. The data are fetched and retrieved by the Client.
HBase vs HDFS

improt HBase源代码到Eclipse里面:
- mvn clean install -DskipTests
- mvn eclipse:eclipse -DdownloadSources -DdownloadJavadocs
HBase 源码入口